Googleクローラを呼び込む
ホームページの引っ越しに伴いWordpressの移行を手抜きして過去記事のURLが変わってしまい、検索で訪れる人が404errorになってしまっているので、改めてクローラを呼び込みました。
クローラ(Crawler)とは、ウェブ上の文書や画像などを周期的に取得し、自動的にデータベース化するプログラムである。「ボット(Bot)」、「スパイダー」、「ロボット」などとも呼ばれ、主に検索エンジンのデータベース、インデックス作成に用いられている
Wikipedea
作業前にサイトマップを作成してサーバーへアップロードしておきます。
サイトマップを作成-自動生成ツール「sitemap.xml Editor」
初めての人は自分のGoogleアカウントへログインして、Google Search Console へアクセス(3枚目の画像)
私の場合は以前にも利用したので Google SearchConsole へアクセスして左上をクリック。
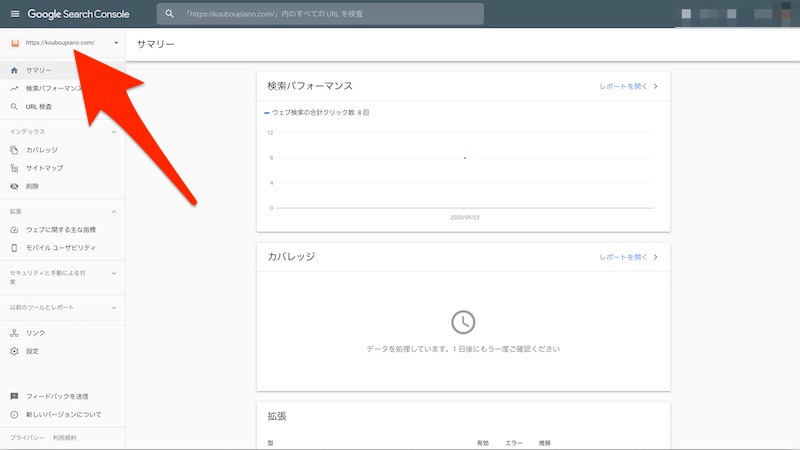
プロパティを追加
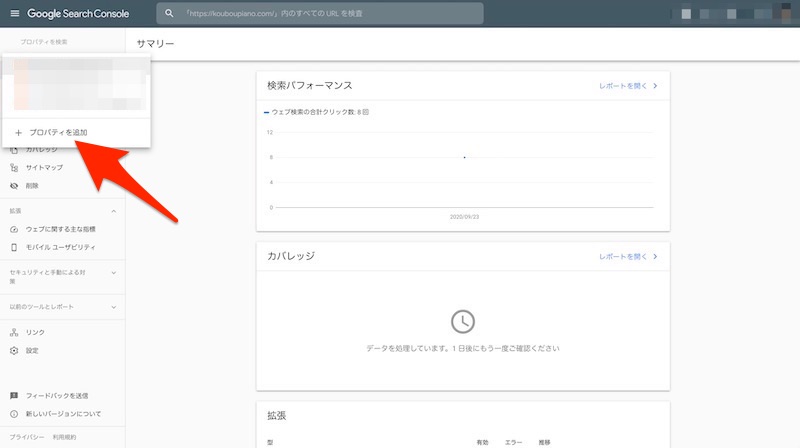
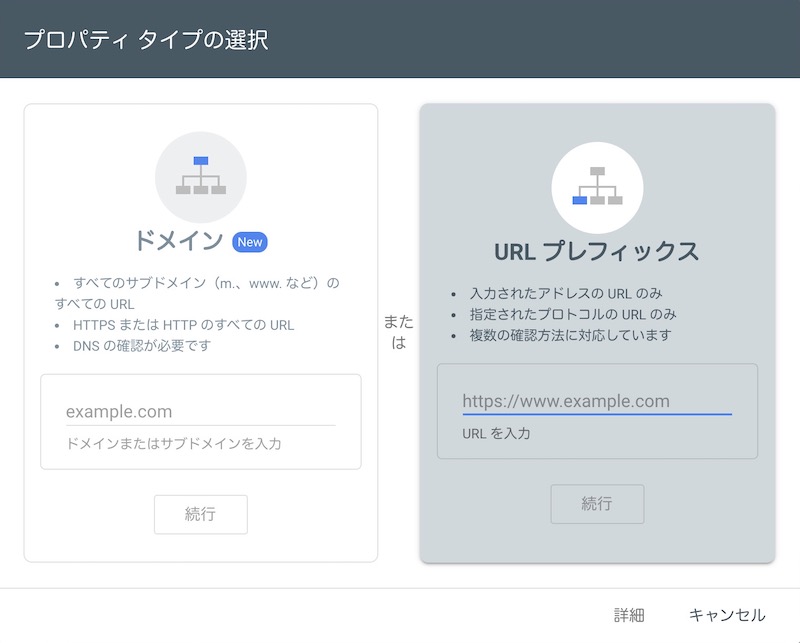
今回は同じドメインで、httpからhttpsに変わっただけなので『URLプレフレックス』を選択しましたが、どっちでも良いのかもしれません。
新しいURLが選択されていることをメニュー左上で確認してから、サイトマップのURLを記入して完了。
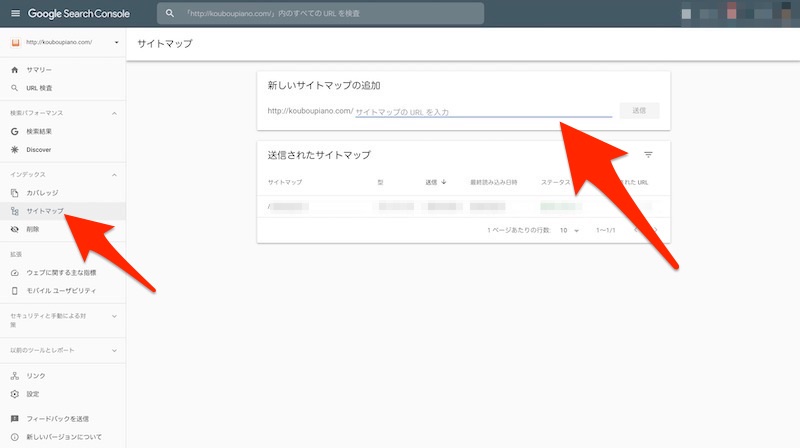
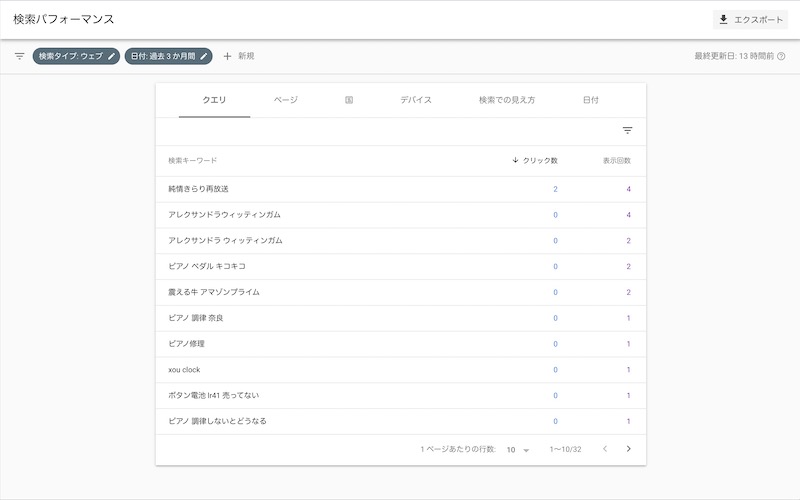
だいたい丸1日から数日で巡回に来てくれるようです。
今朝の時点でこんな感じ。過去記事も正常に検索されているようです。
新しい記事はPubSubHubbub系のプラグインで即インデックスされますが、過去記事が移行前のように検索の上位に来る状態に戻るまでには、まだまだかかりそうです。